










Last updated: 12 March 2024
Web crawling and web scraping are related concepts, but they serve different purposes in the context of retrieving information from the internet. Web crawling is the term for scanning and indexing web resources (usually web pages, but also videos, images, PDFs and other files), while web scraping is the targeted extraction of specific information from those resources.
- What is web crawling?
- What is web scraping?
- The differences between crawling and scraping
- Use cases for web crawling vs. web scraping
What is web crawling?
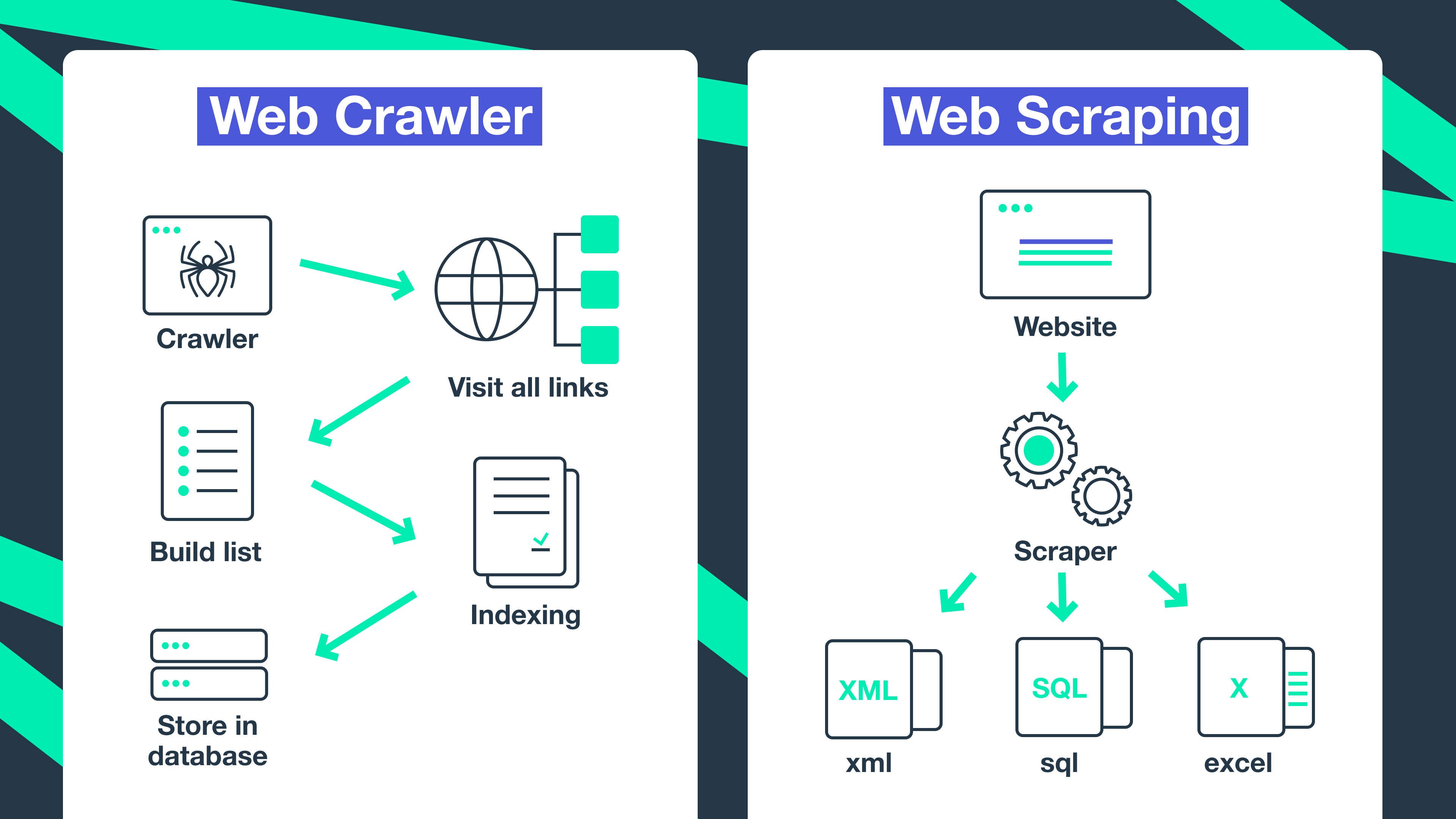
Web crawling is the process of browsing and indexing data from the internet using a program or an automated script. These automated scripts or programs are called web crawlers, web spiders, robots, or spider bots.
Web crawlers systematically browse the internet and index the content they find. This is how search engines like Google collect all the data they need to return results based on your queries.
Web crawling process
Web crawlers begin by fetching the robots.txt file from a website. This file provides directives to web crawlers, indicating which areas of the site are off-limits or restricted. It helps the crawler understand the site's rules and limitations.
The web crawler starts visiting the allowed pages and downloading their content. It begins by fetching the HTML of a page, and then it identifies and extracts hyperlinks on that page. As the crawler finds hyperlinks on the pages it visits, it adds these new URLs to its queue for future exploration. Following hyperlinks allows the crawler to discover additional pages on the website.
The web crawler fetches pages, extracts links, and discovers new URLs until it has covered the desired portion of the website or the entire site.
Once a web crawler has crawled a website, the information is stored and organized in an index for quick and easy retrieval. The process of storing and organizing this information is called indexing. For example, search engines like Google index pages from websites they have crawled. If a page is not indexed, a search engine will not be able to return results from that page.
What is web scraping?
Web scraping is the process of using bots to extract specific data from a target website. Web scraping uses web crawlers to scan and store all the content from a webpage (or a set of webpages) and then uses a web scraping tool or script to extract specific data from that content. Web scraping is sometimes called data harvesting or data extraction.
For example, web scraping can be used to extract weather data from multiple sources, allowing you to create a customized dataset for detailed climate analysis and predictions. In e-commerce, web scraping can be used to collect product information from multiple sources to ensure your prices are competitive.
Sometimes, websites use anti-scraping technology such as CAPTCHAs, which can slow down or even block your scraping attempts. To avoid these blocks, you can route your requests through a proxy server, which will change your IP address.
Web scraping process
Web crawlers visit the target URL(s) to scan and store all the HTML code. The scraping tool or script then uses locators to identify the necessary data in the HTML code, and parses the data string that contains the information to be scraped. The web scraper tool then converts the scraped data into the desired format and transfers it to the appointed storage location.
The difference between crawling and scraping
Crawling and scraping are two different processes that can be used together. Web crawling plays a crucial role in the initial stages of web scraping by fetching web pages that the dedicated web scraping tools use to parse and extract the desired data. This combination of web crawling and web scraping enables the collection of targeted data from websites.
| Web crawling | Web scraping | |
| Used bot | Crawler or spider | Scraper |
| Main task | Storing all data | Extracts required data |
| Main output | List of URLs | Types of data (determined by the user - e.g. prices or descriptions) |
| Manual alternatives | Clicking through each link and storing the URL in a list | Copying and pasting required data into a database |
| Coverage | Reaches all pages | Can be selective |
| Scale of operations | Usually large | Small to large |
| Main applications | Search engines | Diverse (from academia to business) |
| Data deduplication | Filters out duplicates | Not always necessary |
Use cases for web crawling and web scraping
Web crawling and web scraping are used for different purposes. Web crawling has fewer uses than web scraping, but is used on a wider scale. Web scraping is used for more niche purposes than web crawling, and the applications are wider.
Use cases for web crawling
The primary use case for web crawling is to facilitate search engine indexing. Crawlers like Googlebot systematically explore the web by following links and indexing the content they find. Google can then retrieve this information from its archive quickly when you make a query in its search engine.
Website administrators sometimes use web crawlers on a smaller scale to check the links on their website are functional and up-to-date, or to monitor the overall health and performance of their websites (e.g. to identify pages that are slow to load).
Use cases for web scraping
Web scraping tools are versatile and have a much wider range of applications. Here are just a few examples of how people use web scrapers.
E-commerce
Retailers use web scraping tools to monitor competitors’ prices, track pricing trends, and adjust their own pricing strategies to remain competitive.
Market research
Businesses leverage web scraping tools to extract data from websites and social media platforms on market trends, consumer opinions, and competitor activities.
Content aggregation
Content aggregators use web scraping tools to gather and consolidate information from multiple sources, creating comprehensive databases or feeds.
Lead generation
Sales and marketing professionals use web scraping tools to extract contact information and relevant details from websites, creating targeted lists for lead generation.
News monitoring
Media outlets and PR professionals use web scraping tools to monitor news articles and social media for mentions, sentiment analysis, and media coverage tracking.
Academic research
Researchers and academics use web scraping to collect data for studies, analyze patterns, and gain insights into various fields.
Sports statistics gathering
Sports analysts and enthusiasts use web scraping tools to extract sports statistics, player information, and game results from various sports websites.
Product reviews and ratings
Companies use web scraping tools to extract customer reviews and ratings from e-commerce sites, helping them understand customer sentiment and improve products.
Social media analytics
Social media marketers use web scraping tools to extract data from platforms like Twitter, Facebook, and Instagram for sentiment analysis, follower engagement, and trending topics.
Scrape public data from the web at scale
With SOAX, you can take advantage of over 191 million ethically sourced proxies to ensure your web scraping is fast and efficient, without CAPTCHA blocks or downtime. Our diverse proxy network covers 195 countries and enables data scraping from almost any location while avoiding detection.
If you’re new to web scraping, our customer support team and documentation is available 24/7. You can trial SOAX proxies today for just $1.99.

Lisa Whelan
Lisa is a London-based tech expert and AI enthusiast. With a decade of experience, she specializes in writing about data, web scraping, and cybersecurity. She's here to share valuable insights and break down complex technical concepts for the SOAX audience.
Related posts

Statista forecasts that Google's digital advertising revenue could hit nearly $340 billion by 2027, accounting for about 40% of global digital ad spend. With brands investing heavily i...

A proxy server works as a middleman between you and the internet, handling your requests while keeping your real IP address hidden. By standing between you and the web server, proxies ...

Google Search Engine Result Pages (SERPs) offer a wealth of data, including keywords, ad listings, and website rankings, that can inform marketing research. Python provides a practical...